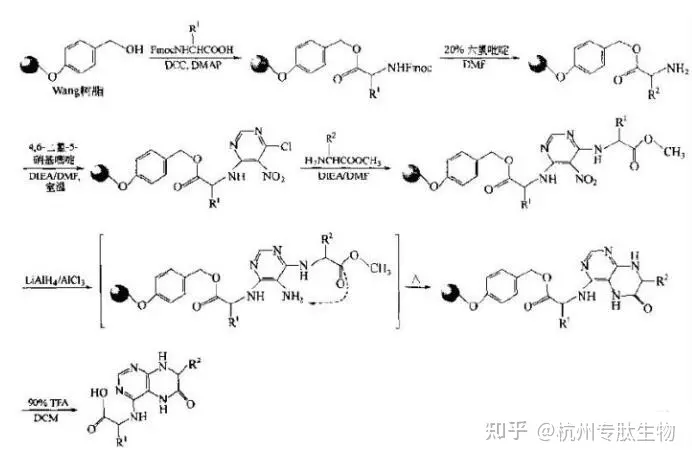
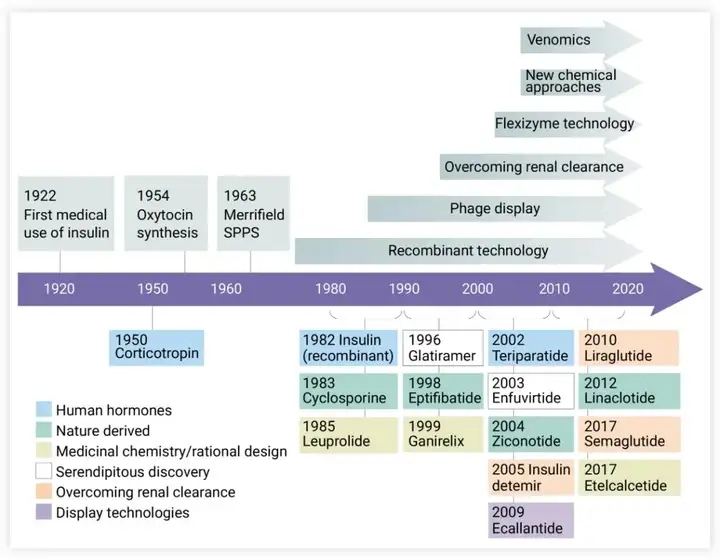
获取数据集后,首先要了解数据的特征(explore data analysis),对数据进行预处理。这里我们围绕以下几点开始!内容有些多,给出一个目录:
去除缺失值
剔除重复值
提取数据集
因变量转换
化合物Lipinsik值计算
可视化
1缺失值处理
去除缺失值:根据IC50值的有无,进行NA值剔除
#IC50 valuedf2 = df[df.standard_value.notna()]# 分子式df2 = df2[df.canonical_smiles.notna()]df2
2重复值处理
去除重复值:根据化合物的分子式,去除同一化合物的重复分析数据
df2_nr = df2.drop_duplicates([canonical_smiles])df2_nr
3提取目标数据集
提取需要的数据集:并不是所有变量都可以用来进行分析,选择需要纳入分析的变量
selection = [molecule_chembl_id,canonical_smiles,standard_value]df3 = df2_nr[selection]df3
4因变量转换
因变量的分布特征:这里因变量为standard_value
,即药物使用的浓度(nM)。
# boxplotax = sns.boxplot(y=”standard_value”, data=df4)ax = sns.stripplot(y=”standard_value”,data=df4, color=”.25″)#密度图sns.distplot(df4[standard_value])
standard_value 分布不均匀,进行转换
# 这里采用Log2转换sns.distplot(np.log2(df4[standard_value]))
# 将dataframe汇总的浓度值,进行log转换,即为logIC50df_combined[logIC50]=[np.log10(m+1) for m in df_combined[standard_value]]df_combined.logIC50.describe()
5计算化合物Lipinski值
计算化合物的Lipinski值:是评估一个化合物能否作为药物,或者一个具有药理学活性或生物学活性的化合物能否成为口服药物的经验法则。由Christopher A. Lipinski对世界药物索引(World Drug Index, WDI)中的2245个进入II期临床的化合物的系统结构特征研究后提出的。
df_lipinski = lipinski(df4.canonical_smiles)df_lipinski
6可视化
简单可视化:分析IC50值高低,与化合物之间的关系
#根据standard_value值,进行高低分组:active,inactivebioactivity_threshold = []for i in df3.standard_value: if float(i) >= 2270: bioactivity_threshold.append(“inactive”) elif float(i) <= 5: bioactivity_threshold.append(“active”) else: bioactivity_threshold.append(“intermediate”)bioactivity_class = pd.Series(bioactivity_threshold, name=class)
查看不同分组化合物的特征
import matplotlib.pyplot as pltdf_2class=df_combined[df_combined[class]!=”intermediate”]#散点图plt.figure(figsize=(5.5, 5.5))sns.scatterplot(x=MW, y=LogP, data=df_2class, hue=class, size=logIC50, edgecolor=black, alpha=0.7)plt.xlabel(MW, fontsize=14, fontweight=bold)plt.ylabel(LogP, fontsize=14, fontweight=bold)plt.legend(bbox_to_anchor=(1.05, 1), loc=2, borderaxespad=0)#boxplot图sns.boxplot(x = class, y = MW, data = df_2class)plt.xlabel(Bioactivity class, fontsize=14, fontweight=bold)plt.ylabel(MW, fontsize=14, fontweight=bold)
结论:
对Target有活性的化合物,其MW相对较高
对Target有活性的化合物,其LogP没有显著差异
合肥科生景肽生物科技有限公司成立于2018年,目前已经打造了全球领先的以肽为核心的生命分子发现、合成生产、结构优化、递送平台,主要瞄准肽发现及靶向递送,专注于为各大制药企业、生物技术公司、科研单位提供一站式的定制化研发服务。 公司独有的KPDS™平台(KS-V Peptide Discovery Services Platform)是国际领先的的多肽药物发现平台,我们致力于创新药物的高效和精准开发,以科生景肽专有KPDS技术为核心,提供一站式,定制化的多肽发现服务,以灵活的产品形式和服务模式助力广大客户各类药物发现项目的快速推进和应用探究,包括但并不限于疾病诊断及保健功能产品、多肽药物、核素偶联药物(RDC)、基于小分子的肽药物偶联物(PDC)和多功能肽偶联物等。中文官网地址:https://www.ks-vpeptide.com.cn/
英文官网地址:https://www.ks-vpeptide.com
领英:https://www.linkedin.com/company/ks-v-peptide/